Date: 2026-03-15
Author: Michael T.M. Emmerich
Every year, on March 14, mathematicians celebrate Pi Day. For my Mathematical Playground blog, I wished to post a short essay on a very, very simple Monte Carlo method for estimating 
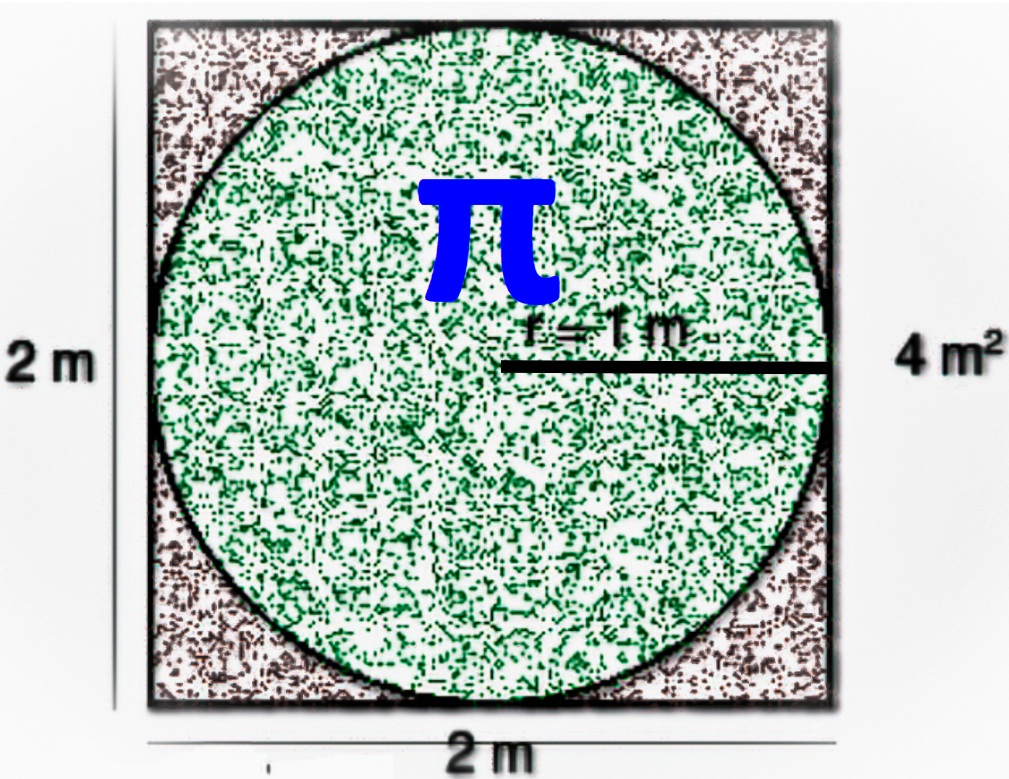
The setup is easy to picture: take the unit circle, meaning a circle of radius 
![[-1,1]\times[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D%5Ctimes%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)


Now throw random points uniformly into the square and count how many land inside the circle. That is the whole idea.
The lovely part is that the computation itself does not use
To make the idea concrete, I also wrote a small interactive Python simulation with an approximate 95% uncertainty band:
Interactive Monte Carlo Pi simulation
A very, very simple geometric idea
The circle has radius

The surrounding square is the set 

If we sample points uniformly in that square, then the fraction of points landing inside the circle estimates the fraction of the square covered by the circle. Since the square area is known, we can estimate the circle area by

But the circle is the unit circle, so its area is exactly

This keeps the method very direct: estimate the area of the unit circle, and you have estimated
Why no knowledge of pi is needed
Suppose a sampled point has coordinates 


Equivalently, and more conveniently for a computer, we check

This is the whole algorithm. No trigonometry. No circumference formula. No prior knowledge of
A tiny Python program
import random
n = 100000
hits = 0
for _ in range(n):
x = 2 * random.random() - 1
y = 2 * random.random() - 1
if x*x + y*y <= 1:
hits += 1
pi_est = 4 * hits / n
print(pi_est)
How to read the code
- The two coordinates are sampled uniformly from
, so the point lies somewhere in the square of side length
- The condition x*x + y*y <= 1 checks whether the point is inside the unit circle.
- The fraction of hits estimates how much of the square is covered by the circle.
- Multiplying by the known square area
An online moving-average version
If one wants to keep the simulation running as an anytime algorithm, there is a neat alternative that updates the estimate directly, without storing the total number of hits. For each sample, define

Then 

In code, this looks as follows:
import random
pi_est = 0.0
for n in range(1, 100001):
x = 2 * random.random() - 1
y = 2 * random.random() - 1
sample = 4.0 if x*x + y*y <= 1 else 0.0
pi_est += (sample - pi_est) / n
print(pi_est)
This online form is mathematically equivalent to counting hits, but it is convenient when one wants to keep a running estimate forever. It uses constant memory and fits the spirit of an anytime algorithm: at every moment, the current value is the best estimate obtained so far.
Why this works
For each sampled point, define an indicator variable

Each 


The estimator of the circle area is then

and because the unit circle has area

This is an example of a Monte Carlo method: a method that uses repeated random sampling to estimate an unknown quantity.
The non-trivial part: how accurate is the estimate?
The estimate itself is easy. The more interesting question is: how much should we trust it after
This belongs to what is often called uncertainty quantification in statistics and computer science. The estimate alone is not the whole story. It is often important to report, in addition, how uncertain the estimate still is.
Let 

The average hit rate 

Because 

Hence the standard deviation is

This formula already shows the key message: the uncertainty decreases only like 
A beginner-friendly estimated 95% band
Of course, the true hit probability

A common approximate 95% uncertainty interval is then

Where does the 


Equivalently,

where 
This is the band shown in the interactive simulation. It gives the reader a sense not only of the estimate itself, but also of how noisy it still is after a given number of samples.
That extra layer – reporting uncertainty together with the estimate – is precisely what makes the simulation more than a toy. It introduces a central statistical idea in a very concrete setting.
Where this sits among methods for computing pi
Monte Carlo estimation is certainly not the fastest way to compute many digits of
So why use Monte Carlo here at all? Because it is conceptually delightful. It connects geometry, probability, simulation, and statistics in one tiny experiment. It also teaches a lesson that is broader than
References
- Archimedes. (1897). The Works of Archimedes. Edited by T. L. Heath. Cambridge: Cambridge University Press.
- Borwein, J. M., & Borwein, P. B. (1987). Pi and the AGM: A Study in Analytic Number Theory and Computational Complexity. New York: John Wiley & Sons.
- Chudnovsky, D. V., & Chudnovsky, G. V. (1988). Approximation and complex multiplication according to Ramanujan. In Ramanujan Revisited (pp. 375-472). Boston: Academic Press.
- Gentle, J. E. (2003). Random Number Generation and Monte Carlo Methods (2nd ed.). New York: Springer.
- Hammersley, J. M., & Handscomb, D. C. (1964). Monte Carlo Methods. London: Methuen.
- Rubinstein, R. Y., & Kroese, D. P. (2017). Simulation and the Monte Carlo Method (3rd ed.). Hoboken, NJ: John Wiley & Sons.
Try the interactive simulation
You can explore the app here:
https://trinket.io/library/trinkets/e2da81b48f3d
Watch the random points appear, see the running estimate move around, and observe how the 95% band gradually narrows. It is a very simple Pi Day experiment – but also a neat first encounter with uncertainty quantification.
