Michael Emmerich, JYU, Finland, 28.1.2026
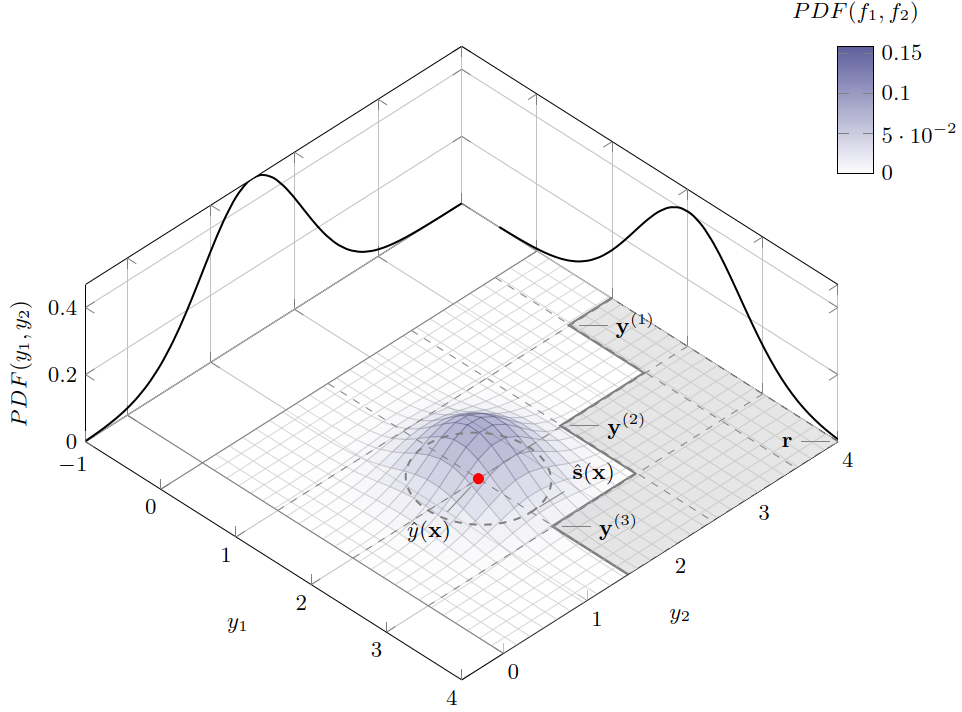
When objective and constraint evaluations are expensive (CFD/FEM, digital-twin simulations, etc.), we often rely on Gaussian process regression (Kriging) as a surrogate. A GP does not only predict a mean vector, it also delivers uncertainty. Interpreted component-wise, this uncertainty naturally forms an axis-aligned confidence box in 

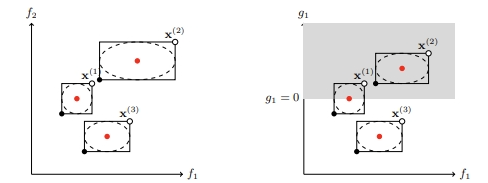
The core ideas go back to my 2005 PhD thesis (Emmerich, 2005) and were worked out for surrogate-assisted multiobjective selection and constraint handling in early 2004-era papers (see our featured bookchapter at the end [9]). A compact discussion of the interval-filter logic is also included in the attached book chapter (Section “Interval Filters,” with the illustrative figure of boxes in objective space and constraint space).
From GP/Kriging prediction to a “confidence box”
Assume minimization of 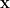





Geometrically, the candidate is associated with the axis-aligned box ![[\text{lb}_\omega(\mathbf{x}),\,\text{ub}_\omega(\mathbf{x})] \subset \mathbb{R}^m](https://s0.wp.com/latex.php?latex=%5B%5Ctext%7Blb%7D_%5Comega%28%5Cmathbf%7Bx%7D%29%2C%5C%2C%5Ctext%7Bub%7D_%5Comega%28%5Cmathbf%7Bx%7D%29%5D+%5Csubset+%5Cmathbb%7BR%7D%5Em&bg=ffffff&fg=000&s=0&c=20201002)
Pareto dominance, now “lifted” to boxes
Recall (minimization): 



With boxes, we ask: can dominance be concluded for sure, or is it only possible depending on how the true values realize inside the boxes?
Certainly reject (certain dominance)
Let 


A simple certain dominance test is:
if 

Intuition: even if
Possibly reject (possible dominance)
A weaker, “there exists a realization” test is:
if 

In practice, “possibly reject” is a tuning knob: using it aggressively increases precision (fewer poor evaluations) but risks losing recall (discarding candidates that could have been among the best). Interval filters make this trade-off explicit (often discussed as error types in pre-selection).
Constrained problems: certain vs possible feasibility
Now add inequality constraints 



-
Certainly feasible: for all
,
.
-
Certainly infeasible (hence certainly reject w.r.t. feasibility): for some
.
- Possibly feasible: otherwise (the confidence interval crosses the boundary for at least one constraint).
A clean constrained-Pareto filter can then be phrased as: (i) reject everything that is certainly infeasible; (ii) among the remaining candidates, use box-dominance tests (above) but prioritize certainly feasible solutions over possibly feasible ones. This is exactly the kind of “interval picture” shown in the objective/constraint panels of the interval-filter figure in the attached chapter.
Where this fits in  selection
selection
Consider we want to shortlist a list that comprises the best 


- Use GP/Kriging or Lipschitz bounds to assign a confidence box to each offspring (and optionally to unevaluated parents).
-
Apply certainly reject rules first. An individual is certainly rejected if its lower bound (best case realization) is dominated by the upper bounds of at least
-
Apply certainly select rule. An individual is certainly among the
- From the remaining set, keep “possibly non-dominated / not certainly rejected” candidates for actual evaluation or for the next ranking stage (e.g., non-dominated sorting of centroids, expected hypervolume improvement, or exploration heuristics). The details for this step and are described in the attached PDF of a preprint.
Note that we deliberately chose confidence region to be box shaped here. As compared to other shapes, this has the advantage that there is only a single “worst case” point (the upper bound vector dominated by all other points in the box) and a single “best case” point (the lower bound vector dominating all other points in the box) in such interval boxes, whereas for other shapes of confidence regions (e.g. circles, see title figure), we would have to deal with Pareto fronts as envelopes for lower and upper bounds.
The key point: GP/Kriging uncertainty is not just “error bars.” Treated as an
- M. Emmerich. Single- and Multi-Objective Evolutionary Design Optimization Assisted by Gaussian Random Field Metamodels. PhD thesis, University of Dortmund, 2005.
- M. Emmerich. Python implementation of dynamic programming for minimum Riesz s-energy subset selection in ordered point sets. Zenodo, 10.5281/zenodo.14792491, 2025.
- M. Emmerich, N. Beume, and B. Naujoks. An EMO algorithm using the hypervolume measure as selection criterion. In International Conference on Evolutionary Multi-Criterion Optimization, pages 62–76. Springer, 2005.
- M. Emmerich, K. C. Giannakoglou, and B. Naujoks. Single- and multiobjective evolutionary optimization assisted by Gaussian random field metamodels. IEEE Transactions on Evolutionary Computation, 10(4):421–439, 2006.
- M. Emmerich, A. Giotis, M. Özdemir, T. Bäck, and K. Giannakoglou. Metamodel-assisted evolution strategies. In International Conference on Parallel Problem Solving from Nature, pages 361–370. Springer, 2002.
- M. Emmerich and B. Naujoks. Metamodel assisted multiobjective optimisation strategies and their application in airfoil design. In Adaptive Computing in Design and Manufacture VI, pages 249–260. Springer, 2004.
- M. Emmerich and B. Naujoks. Metamodel-assisted multiobjective optimization with implicit constraints and its application in airfoil design. In International Conference & Advanced Course ERCOFTAC, Athens, Greece, 2004.
- Limbourg, P., & Aponte, D. E. S. (2005, September). An optimization algorithm for imprecise multi-objective problem functions. In 2005 IEEE Congress on evolutionary computation (Vol. 1, pp. 459-466). IEEE.
- M. T. M. Emmerich. Early ideas and innovations in Bayesian and model-assisted multiobjective optimization. In Challenges in Design Methods, Numerical Tools and Technologies for Sustainable Aviation, Transport and Industry, pp. 93–116, First Online: 28 January 2026. (Computational Methods in Applied Sciences, vol. 17).
(Featured Article: https://doi.org/10.1007/978-3-031-98675-8_8) - https://github.com/emmerichmtm/IntervalParetoFilter/blob/main/README.md
